출처 : https://arxiv.org/pdf/2305.00079.pdf
Abstract
- Fisheye Data
- ADVANTAGE
- Wide FOV (Field of View)
- DISADVANTAGE
- Huge radial distortion
- Neural network performance degradation due to radial distortion
- Difficult to identify the semantic context of the objects if further from the camera center
- ADVANTAGE
- Improvements
- 1.1% higher mAP
- 0.6% higher than SOTA
Introduction
- Fisheye camera sensor: critical to Autonomous Vehicle
- Capture a more holistic representation of the entire scene
- Effective receptive field (180 degrees)
- But radial distortion as a function of distance from the center of the image
- Undistorting the pixel introduces artifacts in the edge pixel & reduces the overall FOV
- Previous Studies with Fisheye camera
- Model Centric Strategies
- Change certain architectural features
- Better conformation to an fisheye feature
- Data Centric Strategies
- manipulate the data (distort/undistort)
- Augment fisheye data
- But both strategies do not guide the model towards learning a representational space that reflects the interaction between semantic and distortion context.
- Model Centric Strategies

- Therefore, this study models the representation space that links the distortion model of fisheye data and its semantic context.
- Underlying distribution of fisheye data reflects Complex interaction between both semantic context & distortion

Fisheye Image Analysis
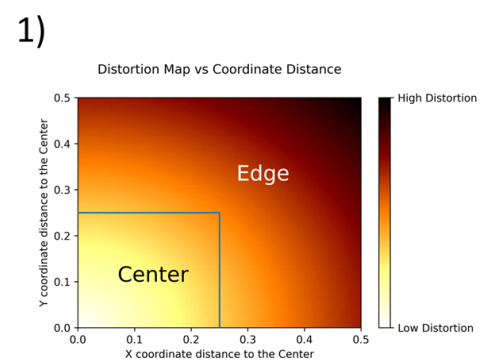
- Specifically, the proposed model extracts Distortion class labels based on an object's distance from the center of the image.
- WHY Distance?
- First, the author estimates the mAP of objects in different regions. Even though the model was not biased towards center objects and the size of the objects has no difference between edge objects and center objects, the mAP of the edge objects is much lower than that of center objects.
- This is because the distortion manifolds of the two objects are different, despite the segmentation class of those two being the same.
- WHY Distance?



- Can we Quantify the distortion?
- BRISQUE ('No-Reference Image Quality Assessment in the Spatial Domain', 2012) shows the amount of distortion in a single image. Natural Image usually shapes like a Gaussian pixel histogram, but the histogram could be modified depending on the distortion.
- BRISQUE helps quantify the distortion by estimating the amount of change.

Methodology
- Enabling the model to recognize both semantic and distortion information.
- 3 Distinct steps: Regional label Extraction -> Pre-training of ResNet-18 (w/ contrastive loss) -> Fine-tuning
1. Regional Class Label Extraction

- Use class information of opendataset to acquire semantic labels.
- Use bounding box information of opendataset to acquire distortion labels.
- If the center of the bounding box is in the inscribed box with an upper left coordinate of (.25, .25) and lower right coordinate of (.75, .75), the object is labeled as a lower of distortion version of its class.
- Total 10 possible distortion classes due to two variants of each of the 5 classes.
2. Contrastive Pre-Training
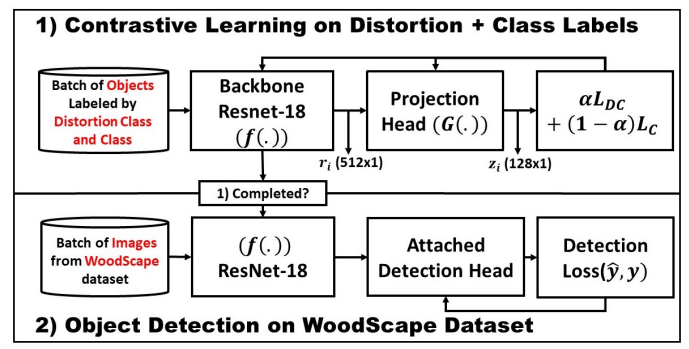
- Perform a contrastive learning objective that constraints the representation to consider both semantic and distortion concepts.
- Contrastive learning is a self-supervised visual representation learning.
- The output of the model would be the representation vector of the corresponding input image.
- The model minimizes the distance between similar representations, so the representation vector of those would be similar as well.
- The model maximizes the distance between different representations, so the representation vector of those would be different as well.
- Find the encoder parameter that minimize the contrastive loss of the two similar vector representations.
- Contrastive Loss quantifies the similarity of two vectors.
- Contrastive Loss = Positive Loss + Negative Loss
- Shape Backbone's representation space (w/ Weighted Contrastive Loss)
- Same semantic class and distortion class to be close to each other
- trained with both semantic & distortion information
- fine-tuned w/ object Detection model
'Computer Vision > Computer Vision' 카테고리의 다른 글
| how to deal with: "Missing or invalid credentials. fatal: Authentication failed for 'https://github.com/username/repo.git'" (0) | 2024.03.06 |
|---|---|
| how to recover my nvidia driver? (0) | 2024.02.22 |
| Optimization (0) | 2022.09.14 |
| Least Squares Method (0) | 2022.09.13 |
| Lucas-Kanade 20 Years On : A Unifying Framework : Part 1 (0) | 2022.09.13 |

댓글