출처 : https://link.springer.com/content/pdf/10.1007/s41095-020-0174-8.pdf
사진출처 : https://en.wikipedia.org/wiki/Constructive_solid_geometry
Constructive solid geometry - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Creating a complex 3D surface or object by combining primitive objects CSG objects can be represented by binary trees, where leaves represent primitives, and nodes represent operations
en.wikipedia.org
사진출처 : https://en.wikipedia.org/wiki/Polygon_mesh
Polygon mesh - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Set of polygons to define a 3D model In 3D computer graphics and solid modeling, a polygon mesh is a collection of vertices, edges and faces that defines the shape of a polyhedral obje
en.wikipedia.org
Abstract
- 2D image를 이용하여 딥러닝을 수행하는 task는 많이 다뤄져 온 바 있습니다.
- 2D image를 이용한 딥러닝은 픽셀을 다루는 문제로 귀결이 되지만, 3D shape는 다양한 표현이 가능합니다.
- Depth
- Multi-view images
- Voxels
- Point clouds
- Meshes
- Implicit surfaces
- 위 서베이 논문에서는 3D Geometry를 사용한 딥러닝의 발전에 대해서 표현방식을 기준으로 다뤄보고자 합니다.
Introduction
- Background
- 분야 : Computer Vision / Computer Graphics System
- 지금까지 3D Modeling의 processing, generation, visualization 관련하여 다뤄져온바 있습니다
- 기술로 치면 3D Shape을 Matching, Identifying, Manipulating 하는 기술이 다뤄져 왔습니다.
- 3D data의 형태는 비정형이기 때문에 (픽셀과 달리) 형태를 나타내고 정의하는 것 자체가 challenging 한 문제입니다.
- 초기의 3D Shape Representation을 보겠습니다.
- 초기에는 Constructive Solid Geometry 나 Deformed Superquadric 을 주로 이용하였습니다.
- 이러한 접근방식은 이미지 recognition이나 3D 복원 등의 task에서 단점이 있을 수 있습니다.
- 이러한 접근방식으로 노이즈를 제거하는 게 힘들 수 있습니다.
- Superquadric 과 같이 고차원으로 표현을 하게 된다면 연산량이 증가하고 모델이 Training Dataset에 오버피팅되는 일이 있을 수 있습니다.
- Constructive Solid Geometry란
- Computational Binary Solid Geometry라고도 불립니다.
- 심플한 object들 (Cuboids, Cylinders, Pyramid, Prisms) 을 Boolean 형식으로 쌓아올려 하나의 Complex Object를 만드는 것을 의미합니다.
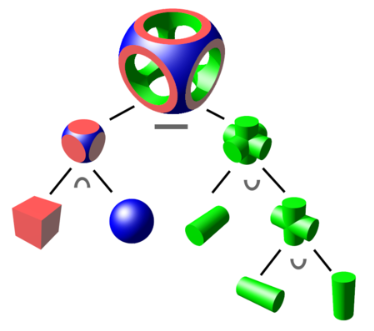
- Deformed Superquadric 란
- Superquaeric에 약간의 변형을 조금씩 줘서 만들어지는 Object을 의미합니다.

- Depth and Multi-view Images
- RGB-D Images
- RGB/RGB-D 형식의 Multi-view Images
- 이미지 형식은 Geometric한 디테일이 떨어지는 형태이긴 합니다.
- Voxels
- pixel의 3D 로의 확장형태
- Voxel 형식도 정형적인 구조를 가지고 있기 때문에 2D Image Representation 학습방식을 쉽게 차용할 수 있습니다.
- 하지만 2D Image를 학습시키는데 사용되는 아키텍처에서 한 차원을 더 추가하는 것은 메모리와 연산시간에서 부하가 많이 생기는 일일 수 있습니다.
- Surfaces
- Pointclouds
- 3D Point Coordinate
- Connectivity Information 문제가 있습니다 (아무래도 라이다 데이터는 Sparse한 문제가 있어서, 중간에 빈 곳을 Dense하게 메꿔줘야하는 문제가 있을 수 있습니다)
- Max Pooling과 같은 Order Invariant Operator를 사용하여 Orderless한 문제를 해결합니다.
- Meshes
- 3D shape를 최소한의 메모리와 연산시간으로 표현할 수 있는 모델입니다.
- Graph-based CNN 에서 주로 쓰입니다.
- Mesh는 Vertex set과 Edge set으로 나뉩니다.
- 3D Shape을 변형하는 문제에서 Mesh를 많이 활용하는데, 일례로 Vertice를 변형하면서도 Connectivity는 그대로 유지하는 경우가 있을 수 있습니다.
- Pointclouds

- Implicit Surfaces
- 앞서 설명한 명시적인 표현들과는 다르게 보다 내재적인 표현을 의미합니다.
- Occupancy Function
- Signed Distance Function
- 3D Shape Object를 훨씬 더 고차원의 표현방식으로 표현할 수 있다는 장점이 있습니다.
- Structured Representation
- 3D Shape을 더 잘 표현하기 위해 Structure 와 Geometric Detail을 따로 분리해서 생각할 수 있습니다.
- Structure에 대해서만 생각한다는 것은, 3D Shape의 각 부분들끼리의 관계에 대해서만 생각한다는 것입니다. (일례로 Symmetry, Supporting, Being Supported 등의 관계가 있을 수 있습니다)
- Deformation-based represenation
- Human body와 같이 Non-rigid 3D Shape을 표현하기 위한 표현방법입니다.
- 컴퓨터 애니메이션 분야나, 증강현실 등에서 주로 쓰이는 방법입니다.
- Intrinsic Deformation Property를 기반으로 합니다. (Rotation-Invariant local feature)
- Geometry Learning
- 앞서 설명한 3D Shape들을 가공하고 생성해서 결과를 만들어내는 딥러닝 방식입니다.
- Geometric Learning의 변천사는 아래 그림처럼 발전해왔습니다.
- 2015년부터 활발히 연구되기 시작한 것을 알 수 있습니다.

Image-based Representations
- 여러 각도에서의 이미지를 통해 하나의 3D Shape을 완성할 수 있습니다.
- RGB에 Depth 정보를 추가하여 Geometric한 정보를 살릴 수 있습니다.
- RGB와 Depth를 각각 별개의 CNN layer에서 다루고 feature를 merge하는 방식
- RGB로부터 Depth를 reconstructing하여 별도의 scale-invariant loss를 두고 학습하는방식
- Depth Map을 Disparity, Height, Angle로 인코딩하는방식
- 3D Object Detection Task
- 3D Object Recognition Task (MVCNN)
- 다른 각도에서 본 이미지를 각각 별개로 처리하고, feature들만 aggregate하는 방식 (View-pooling layer)
- 전통적인 2D Network를 Naive하게 확장시킨 형태로, 성능이 좋지 않습니다.
- 특히 성능이 좋지 않은 이유로 overfitting, orientation, Data sparsity, low resolution 의 문제가 거론됩니다.
- Multi-resolution strategy를 추가하여 정확도를 더 높이는 시도도 존재했습니다.
Voxel-based Representations
- Dense Voxel Representation
- 3D ShapeNets
- Input : Volumetric Representation, Output : Category Labels & Predicted 3D Shape
- Category Label : [Observed / Unobserved / Free] 로 Voxel의 상태를 표현하는 방식
- Deep Belief Network의 pixel data processing 형태를 Voxel로 확장시킨 형태입니다.
- 2차원을 3차원으로 확장시키기 위해 fully connected layer를 fully convolution layer로 치환하였습니다.
- VoxNet
- Volumetric Layer를 처음으로 도입한 네트워크입니다
- 3D-GAN
- Latent Space Vector z로부터 3D Object를 만들어내는 방식
- Denoising Auto-Encoders (DAE)
- VConv-DAE
- 3D-R2N2
- Input : Multiple Image, Output : Reconstructed Objects within an occupancy grid
- 3D ShapeNets
'Deep Learning' 카테고리의 다른 글
| A Holistic View of Perception in Intelligent Vehicles (0) | 2023.07.30 |
|---|---|
| [논문] Self-Distilled Self-supervised Representation Learning (0) | 2023.03.14 |
| Preprocessing Layer 만들기 (0) | 2023.01.07 |
| [개념정리] 딥러닝 성능 용어정리 (0) | 2022.05.07 |
| [개념정리] 딥러닝에서의 Inductive Bias (0) | 2022.05.05 |



댓글